啊哈哈哈,计嵌来咯

第 8 章的整理呢?没了!摆了!
- 第1章 概述
- 第2章 计算机系统的基本结构与工作原理
- 第3章 存储器系统
- 第4章 总线和接口
- 第5章 ARM处理器体系结构和编程模型
- 5.3 Cortex-M3/M4的编程模型 - 堆栈的原理,Cortex-M3/M4处理器的堆栈模型(满递减)及双堆栈结构【了解】
- 第6章 基于ARM微处理器硬件与软件系统设计开发
- 第8章 基于ARM微处理器硬件与软件系统设计开发
- 现在是,缩写时间😎
- 附:考纲
第1章 概述
1.2 计算机系统的组成 - 冯‧诺依曼结构的组成(五个部分)【掌握】
五个主要部分:存储器、运算器、控制器、输入设备、输出设备
(输入设备和输出设备统称为I/O设备,通过外部总线连接到适配器上,进而连接到内部总线上)
- 存储器:主存储器(内存,ROM RAM)辅助存储器(外存,非易失性)
- 在 P267 中,有这样一句话“片上 SRAM 也被成为主存储器”
- 运算器:ALU+寄存器
- 控制器:指令寄存器(IR),指令译码器(ID),操作控制器(OC)
- 输入设备
- 输出设备
- 适配器
- 互联网络(总线):数据总线(Data Bus)、地址总线(Address Bus)、控制总线(Control Bus)
1.3 计算机中数的表示方法 - 理解有符号数的表示方法,会求补码【掌握】
【原码】【反码】【补码】三者对于正数的表示方式是完全一致的
对于负数 x:
- 【原码】的最高位是1(标记这个数是负数)其他位与 x 的绝对值的【原码】一样
- 【反码】的最高位是1(标记这个数是负数)其他位与 x 的绝对值的【原码】相反
- 【补码】等于【反码】+1
有以下【补码 & 原数】的映射关系:
进制相关:
| 进制 | 英文 | 后缀 |
|---|---|---|
| 2 | Binary | B |
| 8 | octal | O |
| 10 | Decimal | |
| 16 | Hexadecimal | H |
关于溢出:(对于有符号数)如果在加法中最高位发生了进位,则 ;如果次高位发生了进位,则 。当且仅当 时,才发生溢出
浮点数:,其中 为符号位, 为尾数, 为阶码
32-bit: len(S)=1, len(M)=23, len(E)=8
64-bit: len(S)=1, len(M)=52, len(E)=11
BCD 码:二进制编码的十进制数,每个十进制数用4位二进制数表示,即每个十进制数用一个四位二进制数来表示,称为BCD码(压缩 BCD 码:每个字节存储两个 BCD 码)
例如:14 对应 0001 0100
第2章 计算机系统的基本结构与工作原理
2.1 计算机系统的基本结构与组成 - 微程序设计思想【理解】
微程序设计思想:将指令的执行过程分解成一系列微操作,每个微操作对应一个微指令,微指令存储在控制存储器中,控制器按照微指令的顺序执行微操作,从而完成指令的执行过程
CISC 指令集复杂,分为指令系统层 - 微体系结构层 - 数字逻辑子层
RISC 指令集精简,分为指令系统层 - 硬核层
冯·诺依曼结构的计算机系统的五大组成部分:运算器、控制器、存储器、输入设备、输出设备
(生僻单词:peripheral 外设)
1 | +-----+ Data Bus +-------------+ |
2.2 模型机存储器子系统 - 存储器分级设计思想(兼顾速度、容量、成本)【理解】
在一些情况下低电平代表有效,即 1;高电平代表 0(一般来说,在后面加上 n 或者 # 代表低电平有效)
一般情况下的存储架构(字扩展来理解)(在这里,默认每个存储体有 8 位):
- 若字长为 则分别有 个存储体
- 地址总线 n-bit,即 ,意味着每个存储体的地址空间为
- 字节选择信号 m-bit,某一位有效意味着需要存取对应存储体的数据
- 总空间 ,总线宽度
Intel 8086 系统的存储架构(辅助理解,不需要考):
- 1MB 内存空间,分为 20 位地址空间,即 2^20 = 1MB
- 内存空间分为两个 512KB 的存储体,被称为高位字节存储体和低位字节存储体
- 地址传入 和 共 22-bit
- 和 分别控制高位字节存储体和低位字节存储体的选中与否(如果其中只有1个有效,意味着只选中了其中一个存储体,剩下的8位总线不传输数据)
- 传输访问的地址
2.2 模型机存储器子系统 - 小端和大端格式(基本概念);字长与字的对齐【了解】
- 小端格式:低地址存放低位,高地址存放高位
- 大端格式:低地址存放高位,高地址存放低位
注意单个字节内,顺序永远是小端格式。事实上讨论字节内的端序是无意义的,一般我们以 byte 作为最小单位,而不是 bit
读取数据流程图
1 | +-----+ [Data Bus] <== fetched data +---------+ |
写入数据流程图
1 | +-----+ [Data Bus] ==> data to write +---------+ |
存储器分级(从快到慢,从小到大):
- 寄存器(Register):CPU 内部,最快,最贵,最小
- 高速缓存(Cache):CPU 内部,快,贵,小
- 一级缓存(单CPU内)两个/核(数据+程序)
- 二级缓存(单CPU内)
- 三级缓存(多核共享)
- 主存储器(Main Memory):CPU 内部,慢,便宜,大
- 辅助存储器(Auxiliary Memory):CPU 外部,最慢,最便宜,最大
2.4 模型机指令集和指令执行过程 - 模型机指令执行流程(结合汇编编程、指令翻译、寻址方式、流水线原理)【掌握】
模型机常用汇编指令(RISC 风格)
下方中 Rd 一般代表目的寄存器(destination register),Rs 代表源寄存器(source register)
指令虽然很多,但是整体还是比较清晰的,可以分为以下几类:
- 二元算术指令:加法
ADD, 减法SUB, 与AND, 或OR等等
形式:ADD Rd Rs1 Rs2其中 Rs2 也可以是某一个立即数 Imm - 一元算术指令:取反
NOR等等
形式:NOR Rd Rs1 - 读取写入:
LDR读取,STR写入
形式:LDR Rd address,STR Rs address - 寄存器赋值:
MOV
形式:MOV Rd Rs,其中 Rs 也可以是某一个立即数 Imm - 有参数控制类(一般参数都是 address)
形式:JX address,JNX address,JMP address,CALL address
有条件跳转:JX和JNX,其中X是某一个可用的条件标志位,如 Z(结果为 0),N(结果为负),C(进/借位),O(溢出)等等
无条件跳转:JMP
调用子程序:CALL(RET用于返回) - 无参数控制类:过程返回
RET,停机HLT
采用了流水线技术的 RISC 处理器(如 MIPS)的所有指令执行时间相同(即:单周期处理器):
- 指令周期 = 若干CPU周期(五级流水线:取指,指令译码,取操作数,执行,存操作数)
- CPU周期 = 总线周期 = 若干 T 周期(一个 T 周期为一个脉冲,对应一个高电平+一个低电平)
2.5 计算机体系结构的改进 - RISC与CISC各自特性与区别【了解】
RISC 指令的几个特点(与CISC相比):
- 指令定长
优点:指令译码简单,指令执行速度快,总线一次可以传输一条完整指令
缺点:指令数目有限,立即数长度受限 - 采用 加载/存储(Load/Store)体系架构
优点:简化指令集,提高指令执行速度,仍能完成所有运算
缺点:无法像 CISC 直接采用内存地址作为参数,需要先加载到寄存器中,较麻烦 - 寻址方式简单,种类较少
- 指令集中的指令数量较少
- 每条指令执行时间相同(即:单周期处理器)
- 算术和逻辑运算指令普遍支持三操作数格式
- 只能对寄存器操作数进行算术和逻辑运算(Load/Store 的特性)
- 程序代码量较大,执行复杂操作需要使用较多的简单指令(指令集中的指令数量较少 的特性)
2.5 计算机体系结构的改进 - 流水线基本原理,典型的三级、五级流水线划分,三种相关冲突及解决【掌握】
流水线的基本原理:将指令执行过程分为若干个阶段,每个阶段由一个专门的电路来完成,各个阶段之间采用流水线技术连接起来,使得每个阶段可以并行执行,从而提高指令执行速度(原理:重叠使 IPC 大大增加)
- 三级流水线:取指(Fetch),译码(Decode),执行(Execute)
- 五级流水线:取指(Fetch),译码(Decode),取源操作数(Read),计算执行(Execute),回写结果(Write Back)
理想情况下,流水线的吞吐率是每个周期一个指令;事实上,n 级流水线需要额外插入 n-1 个流水线寄存器
流水线的三种相关冲突:(冒险)
- 资源相关(如总线冲突)
解决方案:哈佛结构(指令与数据用两套独立的总线),插入气泡(阻塞) - 数据相关(后一条指令需要用前一条的结果)
解决方案:优化编译器,数据旁路(直接把结果传给需要的指令),插入气泡 - 控制相关(如条件跳转)
解决方案:转移延迟槽(在跳转指令后面插入一条指令,使得跳转指令后面的指令也能执行),动态转移预测(预测跳转的目标地址)
第3章 存储器系统
3.2 只读存储器 - 地址译码,字线、位线【理解】
ROM(Read Only Memory):只读存储器,只能读取,不能写入【特殊情况可以写入】
- 掩模ROM(Mask ROM):只读(值由 mask 决定)
- 可编程ROM(PROM,Programmable ROM):一次性可写(可以通过烧断熔丝来改写,但是不可逆)
- 可擦除可编程ROM(EPROM,Erasable Programmable ROM):可擦除可写(可以通过紫外线照射来擦除,每次擦除会擦除原有所有内容)
- 电可擦除可编程ROM(E²PROM,Electrically Erasable Programmable ROM):电可擦除可写(可以通过电压来擦除,每次擦除可以擦除指定内容)
闪存 Flash:一种特殊的 EPROM,可以分块擦除,擦除速度比 EEPROM 快,但是寿命比 EEPROM 短
地址译码:
- 共同通过译码对应 中的某一个,每一根 线对应 4 个 bit,通过 输出
- 称为字线(Word Line), 称为位线(Bit Line)(或数据线), 称为地址线(Address Line)
- 一个块有 个 bit
3.4 存储器与CPU的连接 - 地址空间与存储器连接,存储器的位扩展、字扩展【掌握】
原理角度:存储器和 CPU 通过地址总线、数据总线、控制总线连接
工程设计角度:存储器和 CPU 不在一起(CPU 在主板上),通过总线连接
地址空间与存储器连接:
- 地址空间:CPU 可以访问的地址范围
- 地址总线宽度即 CPU 的地址空间大小
- 连接的线:不妨设 CPU 与 块 位的存储器芯片相连接
- : (数据总线)双向传输数据用
- : (地址总线)CPU 单向向 RAM 传输地址用
- :(控制总线)CPU 单向向 RAM 传输,决定是读还是写
- :(地址总线)CPU 单向向 RAM 传输,决定选择是哪块存储器芯片(通过译码器译码,具体而言通过若干取反和与门实现 N 线变 1 线)
- 总共地址总线数量为
- 例:对 4 块 位的存储器芯片相连,
- 双向传输数据
- 决定具体地址
- 决定是读还是写
- 决定选择是哪块存储器芯片(通过译码实现 2 线变 1 线)
存储器拓展:
- 位拓展:将存储器的位数扩展为原来的 倍,即 个 位的存储器芯片并联,变成 位的存储器
实现:简单将 D 线组合在一起即可,A 线, R/W# 线, CS# 线简单并联即可 - 字拓展:将存储器的字长扩展为原来的 倍,即 个 位的存储器芯片并联,变成 位的存储器
实现:将 D 线, R/W# 线, A 线低 M 位部分简单并联,A 线高 N 为部分通过 译码器译码后连入 CS# 线 - 复合拓展:先进行位拓展,位拓展后作为一个整体再进行字拓展。
3.5 高速缓冲 - Cache基本工作原理及作用(仅描述概念即可)【理解】
一个典型 Cache 行包含:缓存数据 512 位,标记信息 14 位,有效位 1 位,一致性控制位 1 位,替换控制位 2 位,共 530 位
多级 Cache
- L1 Cache: 32~256 KB
- L2 Cache: 512 KB(普通微机)>2MB(某些服务器)
- L3 Cache: 早期置于主板,现在置于 CPU,多用于多个 CPU 之间共享数据
命中率
- L1 Cache 80%
- L1+L2+L3 Cache 95%
【不重要】地址映射和转换:
- 全相联映射方式:主存中每个块都有可能在 Cache 中的任何一行中,因此需要比较所有行的标记信息,效率低
查找方式:在块表中寻找块地址,如果找到则命中,否则未命中 - 直接相联映射方式:主存中每个块只能映射到 Cache 中的某一行,因此只需要比较一行的标记信息,效率高
查找方式:比较 Cache 对应行上的标记信息,如果找到则命中,否则未命中 - 组相联映射方式:主存中每个块可以映射到 Cache 中的某一组,组内的行数为 ,因此需要比较 行的标记信息,效率介于全相联和直接相联之间
分块方式:Cache 大小与主存每页的大小相同,Cache 的组大小和主存每组的大小相等,即组外是直接映射方式,组内是全相联映射方式
Cache 块;主存 块
查找方式:比较 Cache 对应组内的所有行的标记信息,如果找到则命中,否则未命中
Cache 更新与替换策略
- 读取结构
- 贯穿读出:CPU 先访问 Cache,未命中再访问主存
- 旁路读出:CPU 同时访问 Cache 和主存,Cache 的数据先传给 CPU,主存的数据后传给 CPU,如果 Cache 命中则主存的数据被丢弃
- 写入更新策略
- 写通方式:CPU 同时写入 Cache 和主存
- 写回方式:CPU 直接写回 Cache,在 Cache 被丢弃时若 Cache 中的数据被修改则写回主存
- 替换策略
- 随机替换:随机选取一行替换
- 最不常用替换(Least Frequecntly Used, LFU):替换一段时间内最少使用的行
- 先进先出替换(First In First Out, FIFO):替换最先进入的行
- 近期最少使用替换(Least Recently Used, LRU):替换 CPU 最近最少使用的行
散装知识点
RAM(来自 3.3)
- SRAM(Static RAM):静态随机存取存储器,速度快,但是容量小,价格高
- DRAM(Dynamic RAM):动态随机存取存储器,速度慢,但是容量大,价格低
第4章 总线和接口
4.1 总线技术 - 总线操作与时序【理解】
总线带宽 = 总线宽度 * 时钟频率 ÷ 8(字节/秒)
总线的分类:
- 按总线位置
- 按芯片内外:片内总线,片间总线
- 按系统内外:内总线(板级总线,系统总线),外总线(I/O总线,通信总线)
- 按总线功能
- 数据总线:双向传输数据
- 地址总线:单向传输地址
- 控制总线:双向传输控制信号
- 按数据传输方式分类
- 串行总线:一根线传输数据
- 单端:一根信号线,一根信号参考地线
- 差分:一对信号差分线
- 并行总线:多根线同时传输数据(时钟频率不能高,否则线间干扰)
- 串行总线:一根线传输数据
- 按时序控制方式分类
- 同步总线:按照相同的时间基准,规定的时钟周期进行数据传输
- 异步总线:收发双方信号,握手
- 半同步总线:平时按照同步总线工作,如果有一方跟不上则按照异步总线协调至同步
- 按时分复用方式分类
- 按照时间片,有时传输数据,有时传输指令
总线的结构
- 单总线结构
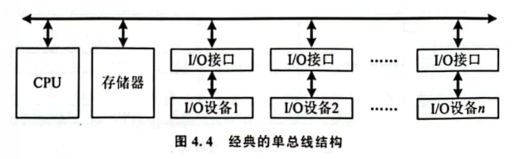
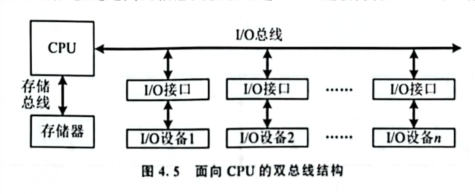
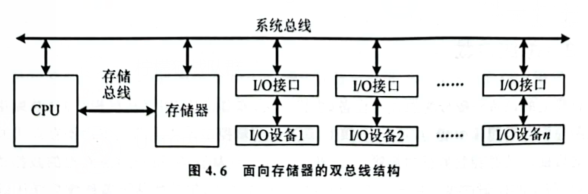
- 双总线结构
CPU 与存储器之间有一条总线,两种的区别在于存储器是否直接和系统总线相联
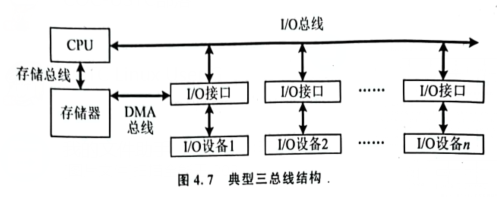
- 三总线结构
存储总线: CPU - 存储器
DMA 总线:存储器 - I/O接口
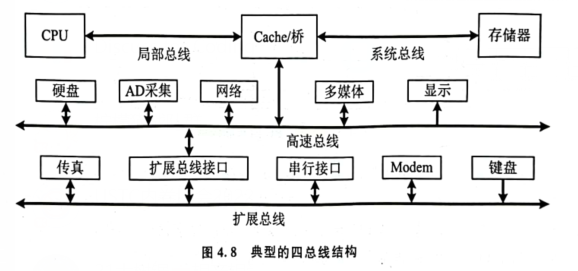
- 四总线结构(最常见)
局部总线:CPU - Cache桥
系统总线:存储器 - Cache桥
高速总线:快速I/O设备 - Cache桥
拓展总线:慢速I/O设备
(高速总线和拓展总线通过拓展总线接口相联)
总线仲裁
- 集中式仲裁
- 串行仲裁 daisy chain 按照远近顺序仲裁
- 并行仲裁 按照优先级仲裁
- 混合仲裁 块内串行仲裁 块外并行仲裁
- 分布式仲裁
- 主设备间自行协商
本质上是按照优先级,如果有优先级更高的设备在使用总线就等待,否则就使用总线(并发出总线请求)(发出请求的时候本质上不是“请求”,而是“通知”)
- 主设备间自行协商
总线操作与时序
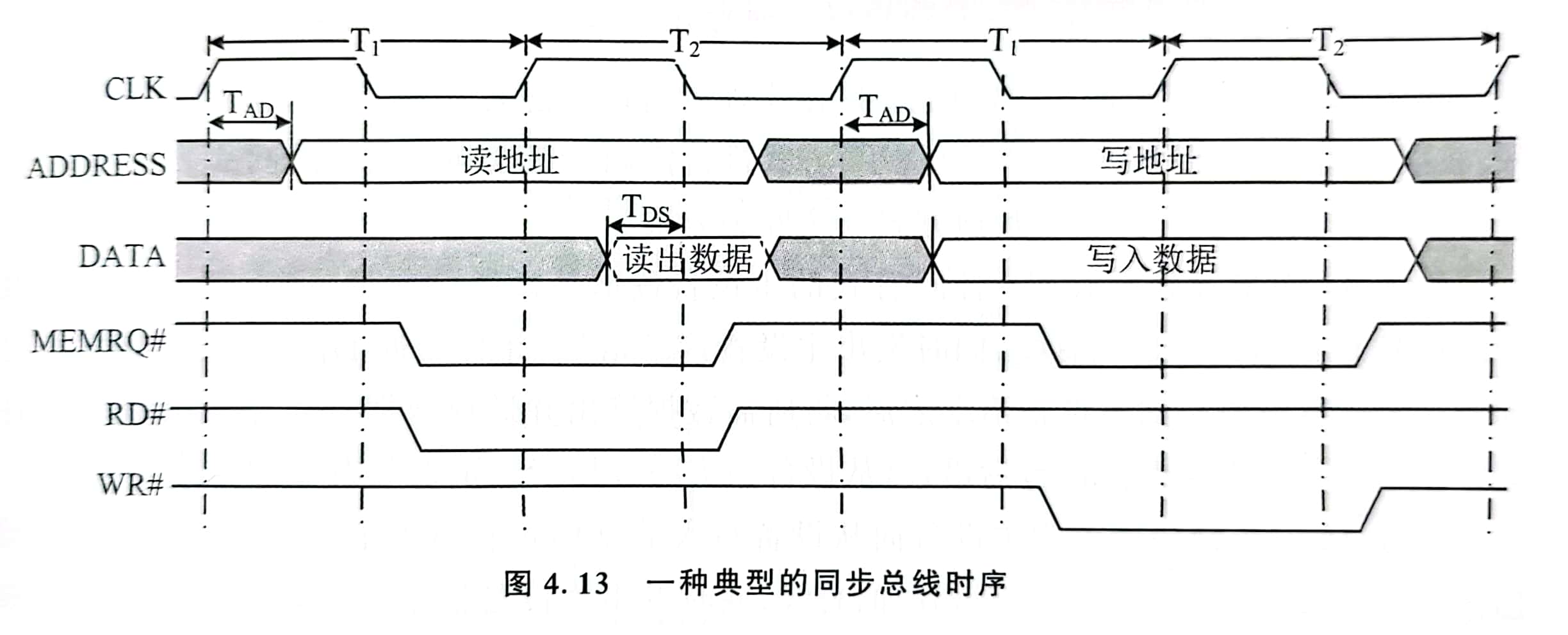
- 同步总线时序
- 收发双方按照统一的时钟工作
- 受制于最慢的设备(总线偏离)
- CPU 与主存储器之间的数据传输
- 时序参数:描述了不同事件之间的时序关系
- 异步总线时序
- 通过双方约定的握手信号对传送过程进行控制
- 分为三种方式:不互锁方式,半互锁方式,全互锁方式
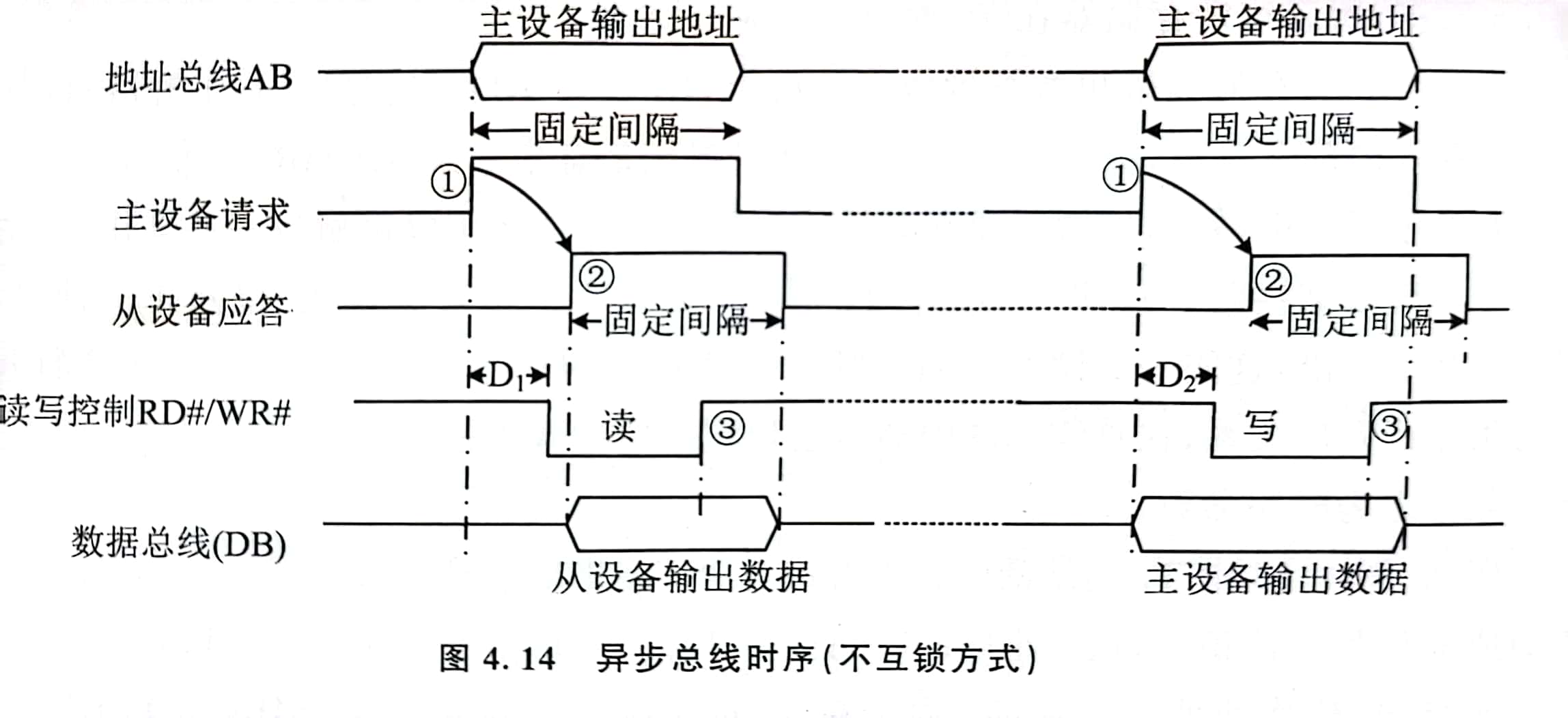
- 不互锁方式:不互锁,请求信号与应答信号在一段时间后自行撤销(认定收到),要求主设备和从设备速度差异在一定范围内(否则导致错误)
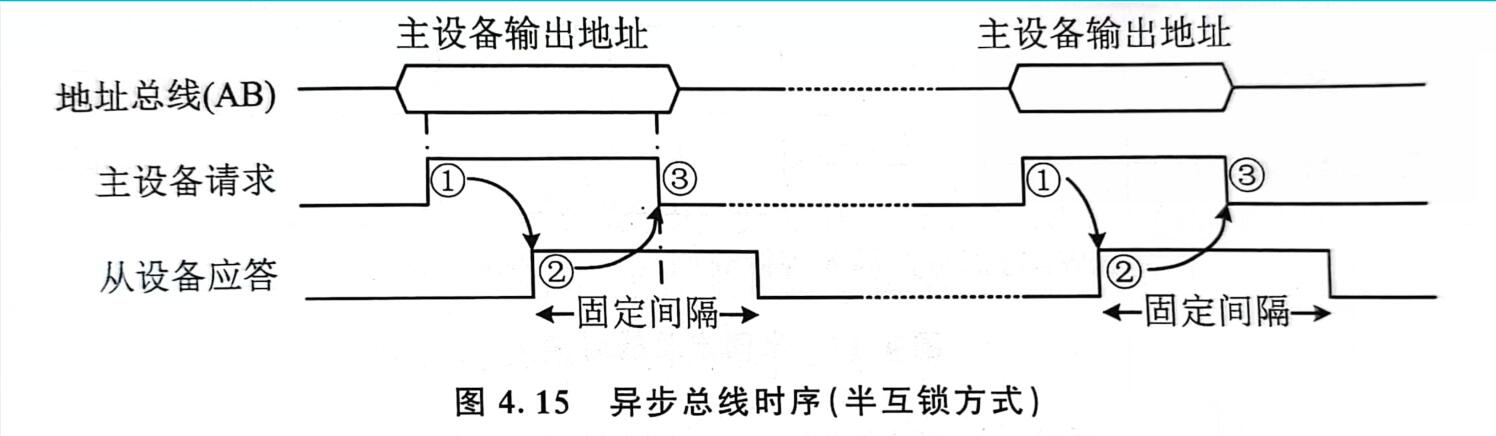
- 半互锁方式:等待从设备的应答之后,主设备才开始读数据,然后撤销请求信号。从设备输出数据和发送应答信号后,不关心主设备数据是否接受完毕,固定一定时间后直接撤销输出数据和应答信号
- 全互锁方式:等待从设备的应答之后,主设备才开始读数据,然后撤销请求信号。从设备输出数据和发送应答信号后,得知主设备撤销请求信号后撤销输出数据和应答信号
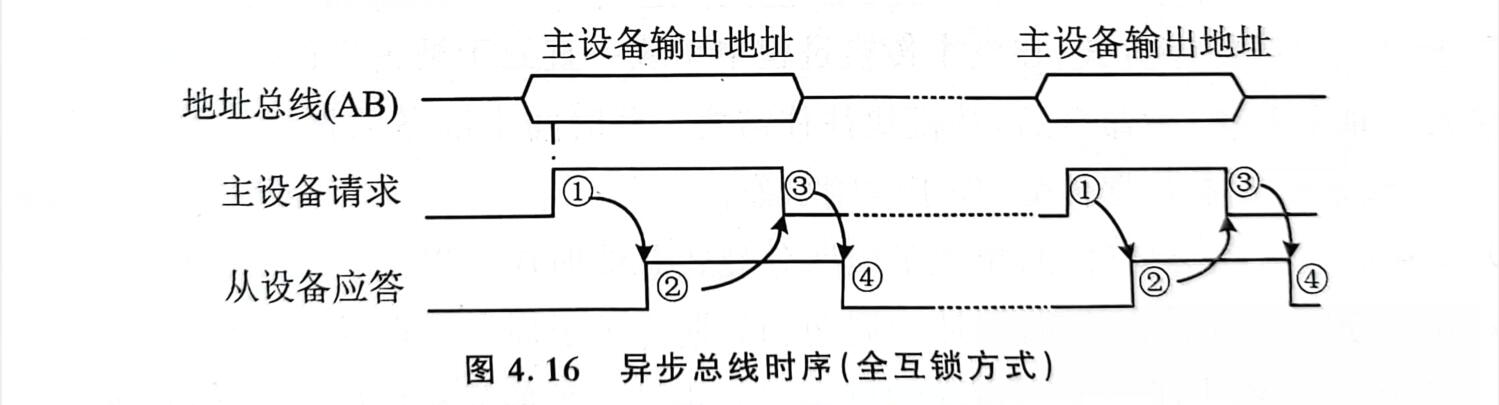
- 不互锁方式:不互锁,请求信号与应答信号在一段时间后自行撤销(认定收到),要求主设备和从设备速度差异在一定范围内(否则导致错误)
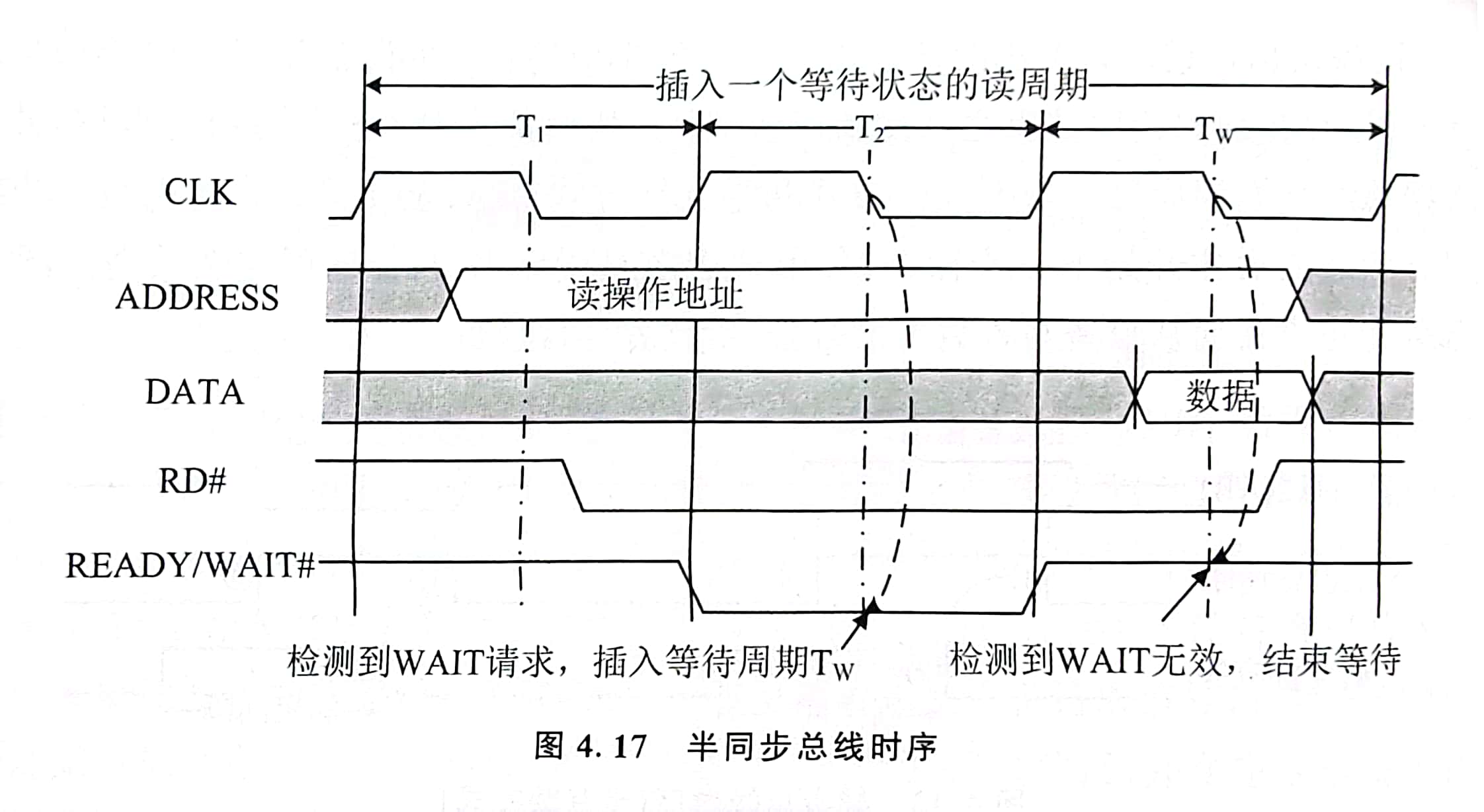
- 半同步总线时序
在同步时序中,若主设备和从设备速度差异较大,从设备通过 READY/WAIT# 线向主模块提出要求(表示尚未准备好)请求主模块延长时钟周期
- 周期分列式总线时序
- 上面三种中,传输过程中总线一直处于被占用的状态。实际系统中,总线的使用率很低,因此可以将总线周期分为几个阶段
- 以读存储器操作为例,分为寻址子周期和数据传送子周期。
- 寻址子周期发送地址,读命令和主模块识别码(ID编号),随后释放总线。
- 从模块准备好后,向主设备发起总线申请,获准后启动数据传送子周期,从模块输出数据和主模块识别码(ID编号),相关主模块接收数据,随后释放总线
- 分列式操作减少了总线资源的无效占用,从而提高了总线的利用率
4.2 片内总线AMBA - AHB数据传输过程,AHB“流水线”分离操作【理解】
AMBA(Advanced Microcontroller Bus Architecture):高级微控制器总线结构,ARM 公司提出的一种片内总线标准
AMBA2
- AHB(Advanced High-performance Bus):高级高性能总线,主要用于连接处理器和存储器
- ASB(Advanced System Bus):高级系统总线,主要用于连接处理器和外设
- APB(Advanced Peripheral Bus):高级外设总线,主要用于连接外设
典型结构:基于一条高性能系统中枢(AHB / ASB),连接多个低性能外设(APB)。AHB / ASB 与 APB 之间通过桥接器(Bridge)(AHB-APB / ASB-APB)相连
AMBA2 信号命名规则
- 信号名是大写字母
- 信号名前缀
- AHB: H
- ASB
- 主机和仲裁器之间的单向信号:A
- ASB 信号:B(eg. BWRITE)
- 单向的 ASB 译码信号:D
- 测试信号加前缀:T-
- 低电平有效信号名后缀:-n
AHB 信号定义,AHB仲裁信号(P163)
ASB 信号列表(P173)(ASB不支持突发传输)
APB 信号列表(P174)(APB不支持流水线)
AHB 数据传输过程
首先,主设备通过 HBUSREQx 向仲裁器发起总线请求,仲裁器通过 HGRANTx 向主设备发出总线授权,随后主设备发送驱动地址信号和控制信号
- 单个数据简单传输(地址阶段,数据阶段)
- HCLK 时钟信号
- 地址阶段:HADDR 地址信号,控制信号
- 数据阶段(可能存在多段):HWDATA(或 HRDATA)数据信号,HREADY 是否已准备好传输
- 单个数据简单传输中插入等待状态
同 (1),但是 HREADY 会有一段时间为低电平。在 HREADY 变成高电平之前,数据传输不开始 - 多个数据的传输
类似流水线。在上一个数据的地址和控制信号发送完毕之后,下一个数据的地址和控制信号就可以发送了。当上一个数据传输完毕后,下一个数据的数据信号就可以发送了(此时地址和控制信号才撤去) - 流水线分离
- 如果从机不能在下一个时钟周期相应,可以通过 HRESP[1:0] 发出启动 SPLIT 传输的响应(此时仲裁器会将总线使用权让给其他主机)
- 从机做好数据传输准备后,通过 HSPLITx[15:0] 发出重新启动传输信号,主机根据优先级适当重新分配总线使用权
- HMASTER[3:0] 记录当前使用总线的主机编号,HSPLITx[15:0] 中应对对应的主机编号置 1(HMASTER 为一个 0~15 的二进制数,HSPLITx 的 16 位分别对应 16 个主机)
AHB 仲裁过程
- 主机通过 HBUSREQx 信号发出对总线的请求(若希望使用时锁定资源,需要同时发出 HCLOCKx)
- 仲裁器通过 HGRANTx 指示主机 x 获得总线使用权
- 若 HREADY 有效,仲裁器通过改变 HMASTER[3:0] 以指示当前获得总线使用权的主机号
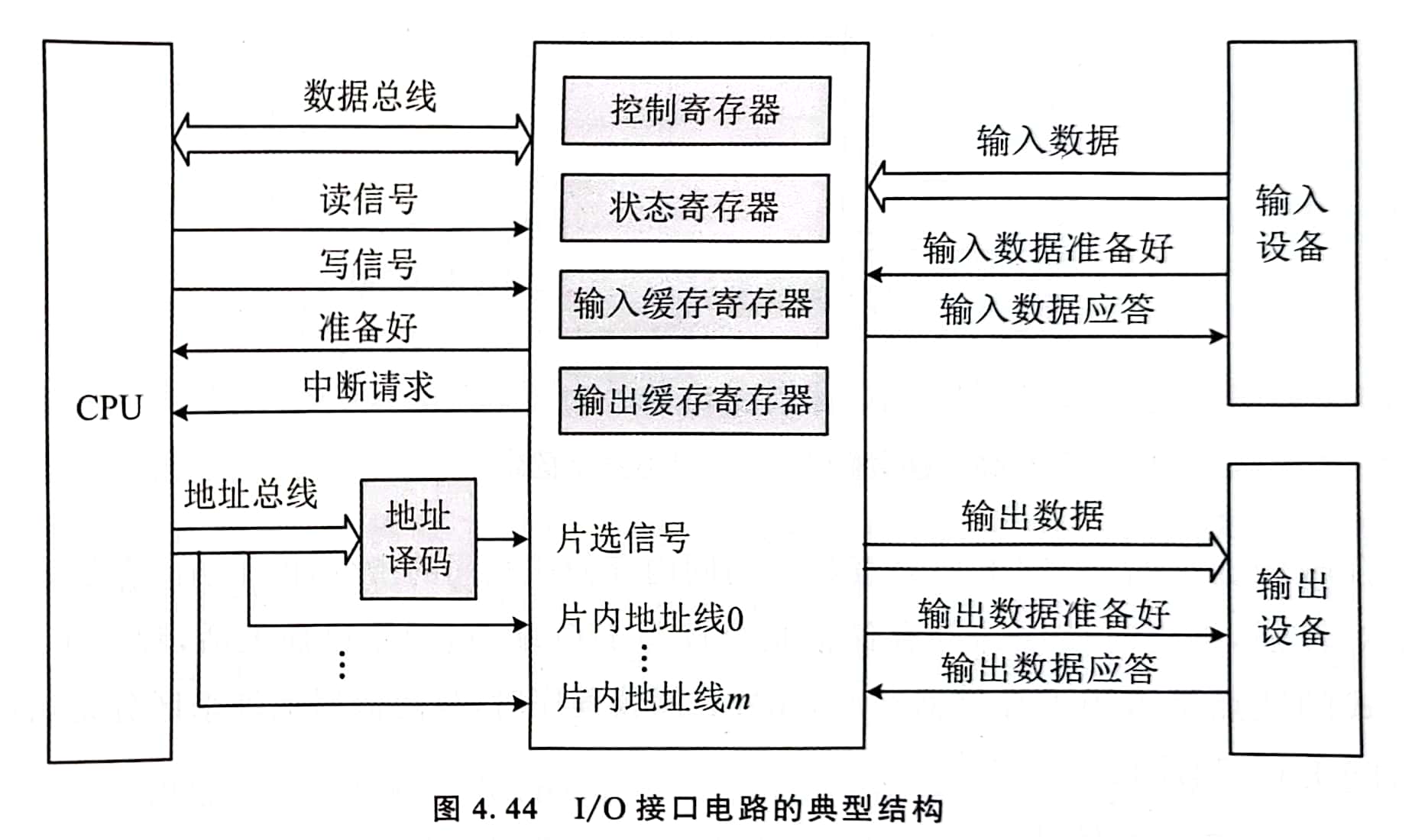
4.4 输入/输出接口 - I/O接口电路的典型结构【了解】
第5章 ARM处理器体系结构和编程模型
5.1 ARM体系结构与ARM处理器概述 - 微架构的概念、哈佛结构的特点以及与冯‧诺依曼结构的区别【了解】
微架构(Microarchitecture):ISA 的硬件实现方式,即数字电路以何种方式来实现处理器的各种功能,包括运算器,控制器,流水线,超标量和存储系统结构等内容,也就是计算机的组织和实现技术
同一个 ISA 可以通过不同微架构来实现,但是只要基于同一个 ISA 即使使用了不同的微架构,也能在软件层面做到互相兼容
处理器的分类:
-
基于 ISA:CISC,RISC
这一部分的区别可以在 2.5 中找到 -
基于微架构:冯·诺依曼结构,哈佛结构
- 冯·诺依曼结构:指令和数据共用一条总线,存放在同一个存储器中,访问都是通过同一个总线进行的
- 哈佛结构:指令和数据分开存放,指令和数据分开传输,指令和数据分开访问,指令和数据分开处理
- 【优点】可以消除取指和取操作数之间的资源相关
- 【优点】指令数据分开存储,指令和数据宽度可以不同
- 【优点】提高了存储器,总线,CPU 的利用率
- 【缺点】成本增加
- 【缺点】设计复杂,连接难度较大
-
Cortex-A 是面向移动计算、智能手机、数字电视、企业网络和服务器的高性能处理器
-
Cortex-R 是面向实时应用的处理器,聚焦于高性能实时应用
-
Cortex-M 是面向嵌入式应用的处理器,低成本、低功耗、高性能
大小核技术(bL,big.LITTLE):搭载两个不同类型的内核(一个高性能,一个低性能),根据负载情况自动切换
DynamIQ 技术:搭载多个不同类型的内核(高性能,低性能,中性能),根据负载情况自动切换,实现多种大小核配置方案(如 1+7, 2+6, 4+4)
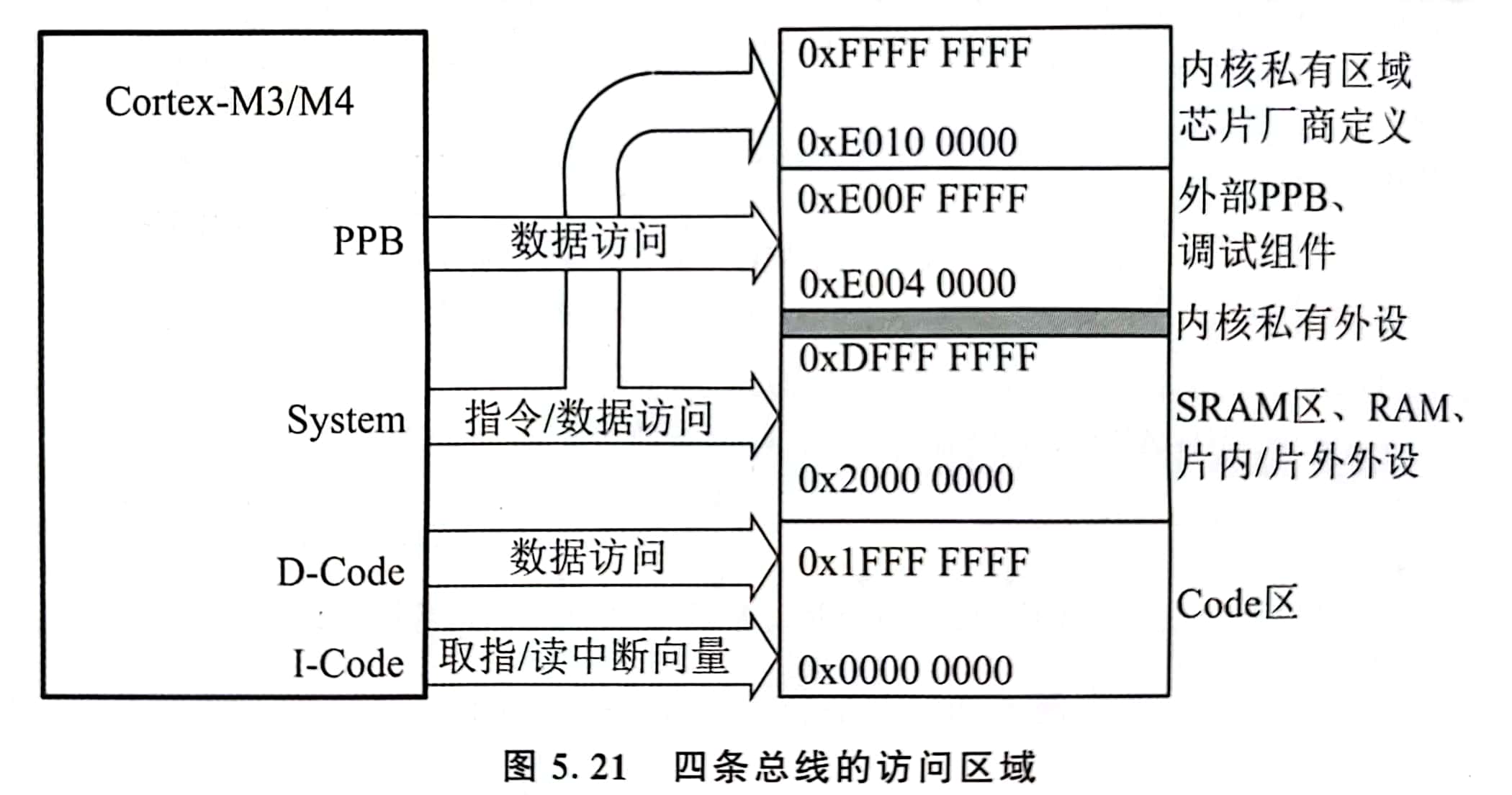
5.2 Cortex-M3/M4处理器结构 - Cortex-M3/M4处理器的存储器映射及总线系统【掌握】
Cortex-M3/M4 的共同技术特性
- 内部有一条三级流水线
- 采用哈佛结构
- 32 位处理器(可以处理 8, 16, 32 位数据)
- 本身不包括存储器,但提供了连接不同存储器的总线接口
- 多种总线接口,可以分别连接存储器、外设以及外部调试接口
- 可以选配 MPU,实现内存的分区保护
- 低功耗,低成本
- 具有丰富的开发调试工具
Cortex-M3/M4 的区别
- 分别基于 ARMv7-M 和 ARMv7E-M 架构
- Cortex-M4 比 Cortex-M3 多拥有一些 DSP 运算指令
- Cortex 可以选配 FPU(浮点数处理单元),可在全部计算完成之后再进行浮点数的舍入,减少舍入误差以提高 MAC 结果的精度
- 增加了支持 8 位和 16 位数据的 SIMD 指令,允许对多个数据同时进行并行处理
- 支持多个(包括SIMD在内)的饱和运算指令,避免在出现上溢出和下溢出时计算结果出现较大畸变
- 支持单周期 16 位、双 16 位以及 32 位乘加(MAC)运算
经典 ARM 处理的 7 种异常:
- 优先级 1: 复位(Reset)
- 优先级 2:数据中止(Data Abort)
- 优先级 3:快速中断(Fast RQ)
- 优先级 4:外部中断(IRQ)
- 优先级 5:预取中止(Prefetch Abort)
- 优先级 6:未定义指令(Undefined)软件中断(SWI)
处理器系统
- WIC
- 睡眠:大部分功能模块的时钟停止
深度睡眠:系统时钟和 SysTick 也被关闭 - 深度睡眠时系统时钟关闭,为了能醒来需要 WIC 信号
深度睡眠状态下出现了 NMI 或者未被屏蔽的 IRQ 时,WIC 触发电源管理单元,将整个系统唤醒
- 睡眠:大部分功能模块的时钟停止
- 调试组件
- JTAG 接口,对寄存器和存储器的访问
- NVIC 有一些用于调试的寄存器,通过这些寄存器对处理器的调试动作进行控制(如停机(halting)和单步执行(stepping)
- CoreSight 调试架构
处理器内部的调试访问接口(Access Port, AP)
外部调试端口(Debug Point,DP)
合称调试访问端口(Debug Access Point,DAP)
存储器管理
- 特性
- 4GB 线性地址空间(AHB-Lite 属于 32 位总线)
- 支持小端和大端(芯片制造商可能只选择其中一种配置类型)
- 支持位带操作 Bit-Band Opertaions(对某一个 bit 取值/赋值)
- 写缓冲。提高程序执行速度
- MPU,内存的分区保护(可选)
- 非对准传送(但额外增加总线传送次数)
- 存储器映射
0x0000 0000 ~ 0x1FFF FFFFCode 区(0.5GB)程序代码访问区域,多采用 Flash 器件0x2000 0000 ~ 0x3FFF FFFFSRAM 区(0.5GB)数据存储区域0x4000 0000 ~ 0x5FFF FFFF片上外设(0.5GB)0x6000 0000 ~ 0x9FFF FFFF外部 RAM(1GB)0xA000 0000 ~ 0xDFFF FFFF片外设备(1GB)0xE000 0000 ~ 0xFFFF FFFF内部私有区域 0.5GB0xE000 0000 ~ 0xE003 FFFF内部私有外设0xE004 0000 ~ 0xE00F FFFF外部私有外设- 芯片厂商定义
- (内部/外部私有外设内的具体地址在 P264 有,感觉不重要没放上来)
总线系统
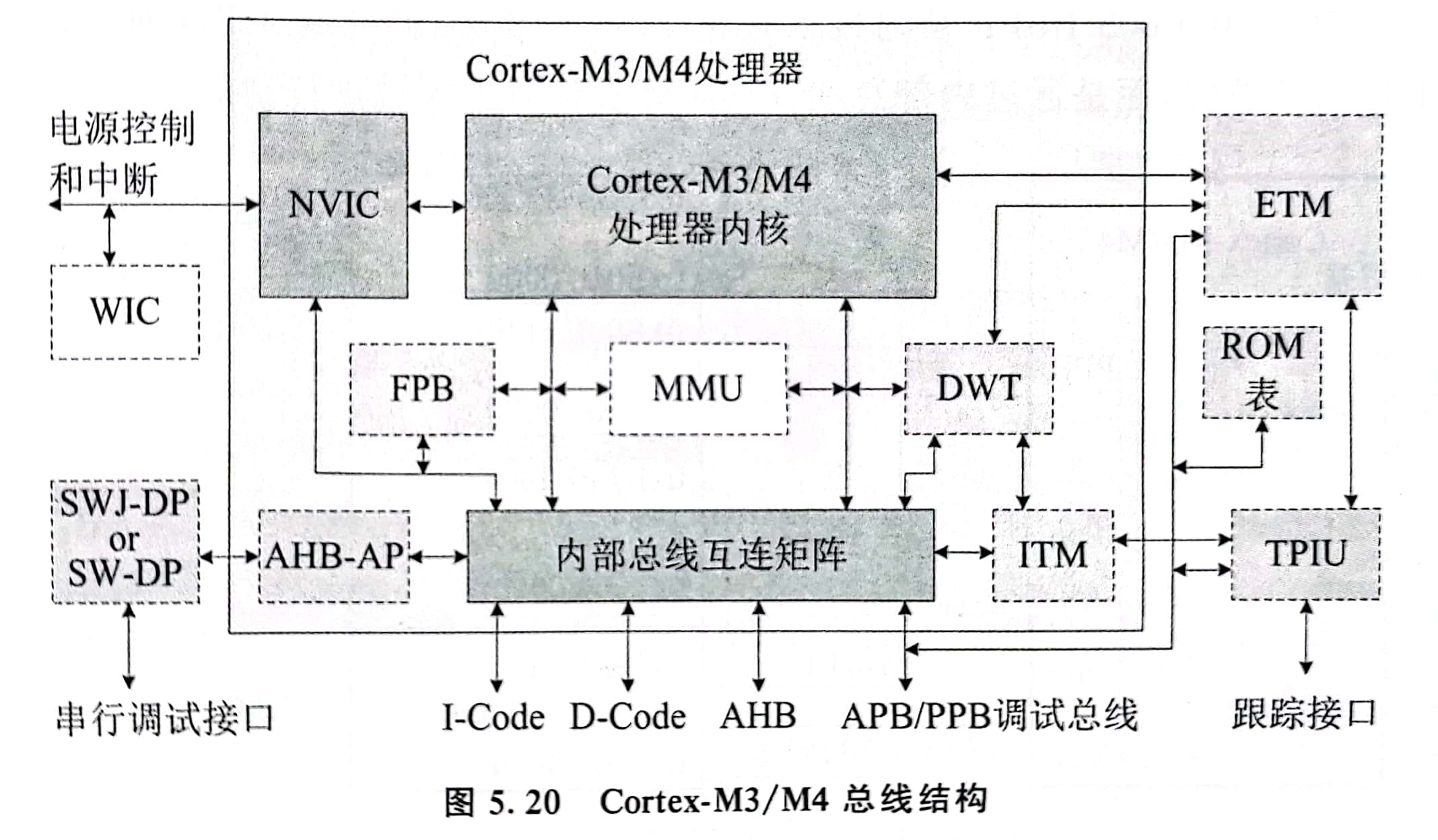
- I-Code D-Code 总线
- 基于 AHB-Lite 总线协议的 32 位总线
0x0000 0000 ~ 0x1FFF FFFF的 Code 区- I-Code 取指操作 D-Code 取数据操作
- 访问空间共用,物理上独立,彼此之间有一个仲裁器(解决冲突)
- Code 区的总线矩阵和总线复用器是两种不同的选件
- 总线矩阵:取指操作和 SRAM 的数据存取操作可以同时进行
- 总线复用器:对 Code 区的访问可以分时进行,不再具有并行性,但能减少芯片电路数和芯片面积
- System 总线
- 基于 AHB-Lite 总线协议的 32 位总线 ,有时称为 AHB 总线
0x2000 0000 ~ 0xDFFF FFFF和0xE010 0000 ~ 0xFFFF FFFF之间的数据传送
- APB/PPB 总线(Private Peripheral Bus)
- 连接
0xE004 0000 ~ 0xE00F FFFF之间的外部私有外设
- 连接
- 调试访问端口 DAP
- 连接内部调试访问端口 AHB-AP 和外部调试端口 DP(SWJ-DP,SW-DP等等)
- AHB-AP 和内部总线互联矩阵之间有一条基于“增强型APB规格”的32位总线
- Cortex-M3/M4 不能直接连接片外存储器,必须使用片外 RAM 控制器作为接口
NVIC 嵌套向量中断控制器(P268,下表有简略)
| 编号 | 类型 | 优先级 | 简介 |
|---|---|---|---|
| 0 | N/A | N/A | 无异常 |
| 1 | 复位 Reset | -3(最高) | 复位 |
| 2 | NMI | -2 | NMI引脚,看门狗/掉电检测单元BOD生成(深度睡眠的唤醒时用到) |
| 3 | Hard Fault 硬件错误 | -1 | 相应的异常处理未使能,所有错误都可能引发此异常 |
| 4~14 | 一堆系统异常 | 可编程 | 7~10,13保留 |
| 15 | SysTick | 可编程 | 系统节拍定时器产生的周期性异常 |
| 16~255 | IRQ#0~IRQ#239 | 可编程 | 由片上外设或外设中断源产生 |
实际情况:MCU 和 SOC 产品的外部中断数量一般只有 8 个或 16 个,很少超过 64 个。另外,某些产品也没有提供外部 NMI 引脚
特性:
- 除了复位,NMI 之外其他所有异常 / 中断都可以被屏蔽
- 除了复位,NMI 和硬件错误之外,其他所有异常 / 中断都可以单独使能或进制
- 除了复位,NMI 和硬件错误具有固定的(高)优先级之外,其他所有异常 / 中断都具有 256 级可编程优先级,可动态修改
- 支持向量中断 / 异常方式
- 向量表可以重定位在存储器中的其他区域
- 低中断处理延迟(零等待存储器系统,中断处理延迟仅为 12 个时钟周期)
- 可由软件触发
- 可以按照优先级进行中断屏蔽
- 进入中断时可以自动保存包括 PSR 在内的多个寄存器,异常返回时自动回复,无需另外编程
- 可选配唤醒中断控制器 WIC 支持睡眠(Sleep)和深度睡眠(Deep Sleep)
中断向量表:
- 地址偏移 = 异常类型(编号)× 0x04(即中断的进入地址)
- CMSIS 中断信号 = 异常类型(编号)-16
SysTick:
- 系统节拍定时器,产生周期性的 #15 SysTick 终端,属于内核设备
- 内部包括一个 24 位递减计数器和如下 4 个寄存器
- 状态控制寄存器(SysTick Control and Status Register, STCSR)
- 加载值寄存器(SysTick Reload Value Register, STRVR)
- 当前计数值寄存器(SysTick Current Value Register, STCVR)
- 校准值寄存器(SysTick Calibration Value Register, STCR)
- 可以通过对这些寄存器的编程操作实现对 SysTick 的管理
- e.g. 每 STRVR 个小周期 STCVR 减至 0,然后发送一次中断
- 有系统保护,只有特权访问等级的用户程序能访问
- 使用 CMSIS-Core 时,有特权访问登记的用户程序可以调用 SysTick-Config 对其进行配置管理
5.3 Cortex-M3/M4的编程模型 - Cortex-M3/M4处理器2种操作状态,2种操作模式,2种访问等级(切换原理)【了解】
2种操作状态
- Thumb 状态
- 执行 Thumb 指令程序代码
- 没有 ARM 状态(因为 Cortex-M 系列处理器不支持 ARM 指令集)
- 调试状态
- 处理器被暂停之后,例如通过调试器发布暂停命令 or 触发程序断点之后会进入
- 可以通过两种方式进入
- 调试器发起暂停请求
- 处理器中调试部件产生调试事件
- 调试状态下,调试器可以访问或修改处理器中寄存器数值
- Thumb 状态和调试状态,调试器都可以访问系统存储器,包括位于处理器片内和片外的各种外设
2种操作模式
- 处理模式
- 即异常处理模式
- 该模式下执行的是异常/中断服务程序(ISR)
- 相当于经典处理器中的5种异常模式整合为一种模式
- 线程模式
- 除了处理模式之外的所有运行模式
- 操作模式又称为处理器工作模式 or 运行模式。Cortex-M3/M4 将经典 ARM 处理器的 7 中运行模式归并成以下两种操作模式
2种访问等级
- 特权访问等级
- 【处理模式】处理器处于处理模式下,正在执行的是异常/中断服务程序,特权访问等级可以访问处理器中的所有资源
- 【线程模式】特权线程模式 sys
- 非特权访问等级
- 【线程模式】非特权线程模式 usr
- 有几条指令无法执行(用法错误异常 Usage Fault)
- 不能访问大部分的内核私有区域,以及某些特殊寄存器(如 NVIC 寄存器)
- 系统中配置了 MPU 且划定某些区域智能特权等级访问(MemManage Fault 异常)
- 处理器处于线程模式时,特权访问等级有特殊寄存器 CONTROL 控制
- 特权模式下可以改变该寄存器以切换模式
- 非特权模式下无法改变该寄存器,只能借助异常机制才能切换模式
- 这是一种最基本的安全模型,可以防止用户程序对系统资源的非法访问
默认:Thumb 状态,特权线程模式
5.3 Cortex-M3/M4的编程模型 - Cortex-M3/M4处理器16个常规寄存器及程序状态寄存器PSR【掌握】
- R0~R12 通用寄存器
- 按位
- R0~R7:低位寄存器(Low Register)
- R8~R12:高位寄存器(High Register)可用于 32 位指令和少数几个 16 位指令(如 MOV)
- 按子程序调用过程
- R0~R3 用于子程序之间的参数传递
- R4~R11 用于保存子程序的局部变量
- R12 作为子程序调用的中间寄存器
- 复位后初始值均未定义
- 按位
- R13:堆栈指针 SP(Stack Pointer)
- 实际上有两个物理栈指针
- MSP(Main Stack Pointer):主堆栈指针,用于处理器的异常处理
- PSP(Process Stack Pointer):进程堆栈指针,用于线程模式下的进程堆栈
- 对于一般程序而言,两个堆栈指针寄存器只有一个可见
- 实际上有两个物理栈指针
- R14:链接寄存器 LR(Link Register)
- R15:程序计数器 PC(Program Counter)
特殊寄存器必须先通过 MSR/MRS 指令对其进行访问
MRS <reg>, <special_reg>
MSR <special_reg>, <reg>- 一般用于表示处理器状态,定义处理器操作状态,设置异常/中断屏蔽
- PSR 程序状态寄存器
- 经典 ARM 处理器(旧,不使用)
- CPSR(Current Program Status Register):当前程序状态寄存器
- SPSR(Saved Program Status Register):保存程序状态寄存器
- ARMv7 开始的
- PSR 代替了 CPSR
- PSR 有 3 种类型(又被称为 xPSR)
- APSR(Application Program Status Register):应用程序状态寄存器
- EPSR(Execution Program Status Register):执行程序状态寄存器
- IPSR(Interrupt Program Status Register):中断程序状态寄存器
- 读写程序状态字
- N(Negative):结果为负
- Z(Zero):结果为 0
- C(Carry):进位
- V(oVerflow):溢出
- Q:饱和,指示增强的 DSP 运算指令是否发生了溢出
- 经典 ARM 处理器(旧,不使用)
- PRIMASK, FAULTMASK, BASEPRI
- PRIMASK:屏蔽所有可屏蔽的异常
- 为 1 时:屏蔽除了复位,NMI和硬件错误以外的所有系统异常,外部中断
- 相当于屏蔽所有 PRI >= 0
- FAULTMASK:屏蔽所有可屏蔽的异常和 NMI
- 为 1 时:硬件错误异常也被屏蔽
- 相当于屏蔽所有 PRI >= -1
- BASEPRI:屏蔽优先级低于某个值的异常
- 虽然有 32 bit,但是只有从下标为 7 开始的若干 bit 有效。若没有配置所有 256 级中断,那么低位 bit 无效。如:
- 配置了 256 级中断,BASEPRI[7:0] 有效
- 配置了 32 级中断,BASEPRI[7:3] 有效
- 配置了 8 级中断,BASEPRI[7:5] 有效
- 数值为多少即屏蔽所有 PRI >= BASEPRI 的中断
- 为全 0 时表示全部不屏蔽(需要屏蔽 PRI >= 0 的时,应使用 PRIMASK)
- 虽然有 32 bit,但是只有从下标为 7 开始的若干 bit 有效。若没有配置所有 256 级中断,那么低位 bit 无效。如:
- PRIMASK:屏蔽所有可屏蔽的异常
- CONTROL 寄存器
- 选择线程模式的特权访问等级 & 栈指针
- 复位后默认为 0(具有特权访问等级)
- SCB 系统控制块
- 功能包括
- 对处理器进行配置
- 提供错误状态信息
- 异常/中断管理
- 反映处理器特性、指令集特性、存储模块特性、调试特性
- 和 NVIC 其他寄存器一起被映射在系统控制控件 SCS 中,地址范围
0xE000 ED00 ~ 0xE000 ED88
- 功能包括
5.3 Cortex-M3/M4的编程模型 - 堆栈的原理,Cortex-M3/M4处理器的堆栈模型(满递减)及双堆栈结构【了解】
- 地址增长方向
- 递增栈(Ascending Stack)
- 栈指针指向栈顶
- 栈顶地址递增
- 一般用于经典 ARM 处理器
- 递减栈(Descending Stack)
- 栈指针指向栈顶
- 栈顶地址递减
- 一般用于 Cortex-M3/M4 处理器
- 递增栈(Ascending Stack)
- 堆栈指针指示位置
- 满堆栈(Full Stack)
- 始终指向栈顶位置
- 空堆栈(Empty Stack)
- 始终指向栈顶下一个位置
- 满堆栈(Full Stack)
- 地址增长方向+堆栈指针指示位置
- 满递增(FA,Full Ascending)栈:SP指向最后压入的数据,且由低地址向高地址增长
- 满递减(FD,Full Descending)栈:SP指向最后压入的数据,且由高地址向低地址增长
- Cortex-M 系列只能使用满递减栈
- 空递增(EA,Empty Ascending)栈:SP指向最后压入的数据的下一个位置,且由低地址向高地址增长
- 空递减(ED,Empty Descending)栈:SP指向最后压入的数据的下一个位置,且由高地址向低地址增长
双字栈对齐模式
- 出现异常时,如果没有到双字边界,会自动插入空字,强制对其
- 同时 xPSR 的第 9 位置为 1,表示堆栈指针发生过调整
- 出栈时如果 xPSR 的第 9 位为 1,应丢弃自动插入的空字
Cortex-M3/M4 的双堆栈模式
- 分别服务于不同的操作模式和特权访问等级
- 本质上在一个栈里(SRAM 中),但是通过两个栈指针来实现
- 高部分存储用户级(PSP初值位于这一段的最高处 P:Process)
- 低部分存储特权级(MSP初值位于这一段的最高处 M:Main)
5.4 Cortex-M3/M4的处理器存储系统 - 位段(位带)操作【了解】
存储器映射:见 5.2 或书本 P288
Cortex-M 多数是小端存储器,但是也有大端存储器的情况
- 大多数经典 ARM 处理器仅允许对齐传输
- 字数据仅能是 4 的倍数
- 半字数据仅能是 2 的倍数
- 字节数据都是对齐的
- Cortex-M3/M4 处理器允许非对齐传输
- 但是会增加总线传输次数
- 例如,对于 32 位数据,如果地址不是 4 的倍数,那么需要分两次传输
位段操作
- 位段和位段别名
- 一次仅能访问一个位
- 有两个预定义的存储器区域支持这种操作
- SRAM 区域的最低 1MB
0x2000 0000 ~ 0x200F FFFF=>0x2200 0000 ~ 0x23FF FFFF - 外设区域的最低 1MB
0x4000 0000 ~ 0x400F FFFF=>0x4200 0000 ~ 0x43FF FFFF
- SRAM 区域的最低 1MB
- 对位段区域的访问没有特殊指令,会被自动转换
- 位段操作的优点
- 代码更加简洁
- C 语言中本身不支持,可以通过
#define人为设置别名使用 volatile 是为了防止编译器做不必要的优化1
2
3
4
5
0x02000000 |
((addr & 0x000FFFFF) << 5) |
(bit << 2))
5.5 Cortex-M3/M4的异常处理 - 异常处理的基本过程,及异常优先级及优先级分组(概念)【了解】
异常处理
- 基本流程
- 异常处理的接受
- 异常进入流程
- 多个寄存器和返回地址被压入当前使用的栈
- 更新内核寄存器和多个 NVIC 寄存器
- 执行异常处理程序
- 异常返回
- 根据终端类型好在异常向量表中查询对应的异常处理程序入口地址,优先级高的异常对应可以打断优先级低的异常处理程序
- 异常状态:
- 非激活状态(Inactive State):异常未被激活,处理器正常运行
- 激活状态(Active State):异常被激活,处理器进入异常处理模式,执行异常处理程序
- 退出状态(Exit State):异常处理程序执行完毕,处理器退出异常处理模式,恢复到非激活状态
- 激活并挂起状态(Active and Pending):异常被激活,但是优先级不够,处理器仍然处于非激活状态
异常优先级
- 3 个固定的最高优先级 -3, -2, -1
- 256 个可编程优先级
- 若芯片设计只实现了 3 位优先级,则 0x00, 0x20, 0x40, …, 0xC0, 0xE0 可用
若芯片设计只实现了 4 位优先级,则 0x00, 0x10, 0x20, …, 0xE0, 0xF0 可用
若芯片设计只实现了 6 位优先级,则 0x00, 0x04, 0x08, …, 0xFC, 0xFF 可用 - 之所以采用低位舍弃,是因为这样在不同的芯片设计下,优先级的大小关系不会发生变化(可移植性)
- 若芯片设计只实现了 3 位优先级,则 0x00, 0x20, 0x40, …, 0xC0, 0xE0 可用
优先级分组
- 8 位优先级配置寄存器分为两个部分:分组优先级和子优先级
- 分组优先级高可以抢占处理
- 子优先级只会在两个相同抢占优先级的中断同时产生的时候起作用
- 优先级分组 0: 抢占优先级域 bit[7:1], 子优先级域 [0]
优先级分组 1: 抢占优先级域 bit[7:2], 子优先级域 [1:0]
优先级分组 2: 抢占优先级域 bit[7:3], 子优先级域 [2:0]
优先级分组 3: 抢占优先级域 bit[7:4], 子优先级域 [3:0]
优先级分组 4: 抢占优先级域 bit[7:5], 子优先级域 [4:0]
优先级分组 5: 抢占优先级域 bit[7:6], 子优先级域 [5:0]
优先级分组 6: 抢占优先级域 bit[7], 子优先级域 [6:0]
优先级分组 7: 抢占优先级域无, 子优先级域 [7:0]
第6章 基于ARM微处理器硬件与软件系统设计开发
6.x 能看懂给出的指令语法及功能说明【了解】
考点内不重要,基本上卷子上会给相关的内容,不做过多整理
以下内容是基于 2.4 的拓展
基础指令
- 二元算术指令:加法
ADD, 减法SUB, 与AND, 或OR等等
(不常用:BIC 位清除Rd|=~Rs,EOR 按位异或,ASR 算术右移,LSL/LSR 逻辑左/右移,ROR 循环右移)
形式:ADD Rd Rs1 Rs2其中 Rs2 也可以是某一个立即数 Imm - 一元算术指令:取反
NOR等等
形式:NOR Rd Rs1 - 读取写入:
LDR读取,STR写入
形式:LDR Rd address,STR Rs address
后缀 S(Signed) 表示有符号数
后缀 B(Byte) 表示 8 位,后缀 H(Halfword) 表示 16 位,后缀 D(Doubleword) 表示 64 位 - 寄存器赋值:
MOV
形式:MOV Rd Rs,其中 Rs 也可以是某一个立即数 Imm - 有参数控制类(一般参数都是 address)
形式:JX address,JNX address,JMP address,CALL address
有条件跳转:JX和JNX,其中X是某一个可用的条件标志位,如 Z(结果为 0),N(结果为负),C(进/借位),O(溢出)等等
无条件跳转:JMP
调用子程序:CALL(RET用于返回) - 无参数控制类:过程返回
RET,停机HLT
拓展指令
- MRS, MSR: 特殊寄存器存取
MRS Rd, Special,MSR Special, Rs - MOVW, MOVT: 16 位立即数赋值
MOVW Rd, Imm16,MOVT Rd, Imm16
MOVW 用于赋值低 16 位,MOVT 用于赋值高 16 位 - MVN:取反后赋值
MVN Rd, Rs
第8章 基于ARM微处理器硬件与软件系统设计开发
略!看实验讲义!整理个鬼!
现在是,缩写时间😎
只记录了笔者认为比较重要(且相对不太常见,有可能错)的缩写,不包含所有缩写
(嗯,我曾经想认真整理这一部分,但是事实上我并没有,所以这里很不全)
- DMA(Direct Memory Access):直接存储器访问
- AMBA2(Advanced Microcontroller Bus Architecture):高级微控制器总线结构
- AHB(Advanced High-performance Bus):高级高性能总线
- ASB(Advanced System Bus):高级系统总线
- APB(Advanced Peripheral Bus):高级外设总线
- DSP(Digital Signal Processor):数字信号处理器
- FPU(Float Point Unit):浮点运算单元
- PC(Program Counter):程序计数器
附:考纲
《计算机原理与嵌入式系统》复习提纲
- 掌握:需要(准确地)记忆、定量计算或编程实现,出现在任意题型中;
- 理解:能够(具体地)说明基本概念和原理,主要出现在填空和简答题中;
- 了解:可以(大致地)运用知识分析、判断给定材料,主要出现在选择和判断题中。
第1章 概述
| 章节 | 知识点 | 要求 |
|---|---|---|
| 1.1 计算机发展简史 | ||
| 1.2 计算机系统的组成 | 冯‧诺依曼结构的组成(五个部分) | 掌握 |
| 1.3 计算机中数的表示方法 | 理解有符号数的表示方法,会求补码 | 掌握 |
| 1.4 嵌入式系统简介 |
第2章 计算机系统的基本结构与工作原理
| 章节 | 知识点 | 要求 |
|---|---|---|
| 2.1 计算机系统的基本结构与组成 | 微程序设计思想 | 理解 |
| 2.2 模型机存储器子系统 | 存储器分级设计思想(兼顾速度、容量、成本) | 理解 |
| 小端和大端格式(基本概念);字长与字的对齐 | 了解 | |
| 2.3 模型机CPU子系统 | ||
| 2.4 模型机指令集和指令执行过程 | 模型机指令执行流程(结合汇编编程、指令翻译、寻址方式、流水线原理) | 掌握 |
| 2.5 计算机体系结构的改进 | RISC与CISC各自特性与区别 | 了解 |
| 流水线基本原理,典型的三级、五级流水线划分,三种相关冲突及解决 | 掌握 | |
| 2.6 Intel x86典型微处理器简介 | ||
| 2.7 ARM嵌入式处理器简介 | ||
| 2.8 计算机性能评测 |
第3章 存储器系统
| 章节 | 知识点 | 要求 |
|---|---|---|
| 3.1 概述 | ||
| 3.2 只读存储器 | 地址译码,字线、位线 | 理解 |
| 3.3 随机存取存储器 | ||
| 3.4 存储器与CPU的连接 | 地址空间与存储器连接,存储器的位扩展、字扩展 | 掌握 |
| 3.5 高速缓冲 | Cache基本工作原理及作用(仅描述概念即可) | 理解 |
| 3.6 虚拟存储器 |
第4章 总线和接口
| 章节 | 知识点 | 要求 |
|---|---|---|
| 4.1 总线技术 | 总线操作与时序 | 理解 |
| 4.2 片内总线AMBA | AHB数据传输过程,AHB“流水线”分离操作 | 理解 |
| 4.3 系统总线和外部总线 | ||
| 4.4 输入/输出接口 | I/O接口电路的典型结构 | 了解 |
第5章 ARM处理器体系结构和编程模型
| 章节 | 知识点 | 要求 |
|---|---|---|
| 5.1 ARM体系结构与ARM处理器概述 | 微架构的概念、哈佛结构的特点以及与冯‧诺依曼结构的区别 | 了解 |
| 5.2 Cortex-M3/M4处理器结构 | Cortex-M3/M4处理器的存储器映射及总线系统 | 掌握 |
| 5.3 Cortex-M3/M4的编程模型 | Cortex-M3/M4处理器2种操作状态,2种操作模式,2种访问等级(切换原理) | 了解 |
| Cortex-M3/M4处理器16个常规寄存器及程序状态寄存器PSR | 掌握 | |
| 堆栈的原理,Cortex-M3/M4处理器的堆栈模型(满递减)及双堆栈结构 | 了解 | |
| 5.4 Cortex-M处理器存储系统 | 位段(位带)操作 | 了解 |
| 5.5 Cortex-M处理器的异常处理 | 异常处理的基本过程,及异常优先级及优先级分组(概念) | 了解 |
第6章 ARM指令系统
| 章节 | 知识点 | 要求 |
|---|---|---|
| 能看懂给出的指令语法及功能说明 | 了解 |
第8章 基于ARM微处理器硬件与软件系统设计开发
| 章节 | 知识点 | 要求 |
|---|---|---|
| 8.1 嵌入式系统设计与开发综述 | 嵌入式系统的交叉开发环境 | 了解 |
| 8.2 嵌入式系统开发过程 | 嵌入式系统开发过程各阶段 | 理解 |
| 8.3 基于ARM内核的常用微处理器 | ||
| 8.4 ARM微处理器最小硬件系统 | 微处理器最小硬件系统概念 | 了解 |
| STM32时钟树的基本概念、功能、作用、意义、特点等 | 理解 | |
| 8.5 嵌入式软件系统设计 | ||
| 8.6 ARM中的GPIO | 给定库函数时GPIO的基本输入输出编程;引脚复用功能 | 掌握 |
| 8.7 定时器 | 定时器(基本和通用)的3种计数模式,普通输入捕获、PWM输入捕获、比较输出、 PWM输出的基本原理 |
掌握 |
| 给定库函数时定时器的基本功能编程,包括硬件连线、相关GPIO口及定时器的初始化配置、 精确延时的实现、结合中断的综合应用 |
掌握 | |
| 8.8 中断控制器 | NVIC的基本概念及特性,中断优先级、向量表、服务函数、设置过程等几个重要概念 | 掌握 |
| 给定库函数时EXTI及NVIC的基本功能编程,包括硬件连线、软件配置(初始化)、简单ISR的编写 | 掌握 | |
| 8.9 USART | 给定库函数时USART简单数据收发功能编程,包括硬件连线、相关部件初始化配置、数据收发操作 | 掌握 |
| 8.10 SPI与I2C | SPI、I2C接口原理(大致传输过程) | 了解 |